- 概述
- 相关内容
- 相关内容
概述
SequoiaDB 通过与 Elasticsearch 配合提供全文检索能力。在 SequoiaDB 中,提供一种新类型的索引:全文索引。该索引与普通索引的典型区别在于,索引数据不是存在于数据节点的索引文件中,而是存储在 Elasticsearch 中。在使用该索引进行查询的时候,会在 Elasticsearch 中进行搜索,数据节点根据其返回的结果,再到本地查找数据。若要使用全文检索功能,在进行部署时,涉及到三种要素:
- SequoiaDB 数据节点
用户通过 SequoiaDB 进行全文索引的管理(创建、删除等),以及使用全文检索条件进行查询。
- Elasticsearch 集群环境
用于存储全文索引数据,以及在索引中进行搜索。每个数据组上的一个全文索引对应 Elasticsearch 上的一个索引,索引名为对应的固定集合名后接 “_” 及复制组名。在进行查询时,根据原始查询条件中包含的全文检索条件进行搜索,并返回结果。
- 适配器 sdbseadapter
作为 SequoiaDB 数据节点与 Elasticsearch 交互的桥梁,进行数据转换与传输等。
以下是一个简略的组网示例。三台主机上分布着 SequoiaDB 的三个复制组的所有数据节点。蓝色为 SequoiaDB 数据节点,绿色为与每个节点对应的适配器节点,最下面为 Elasticsearch 集群环境(单机或集群均可,但生产环境建议部署集群)。
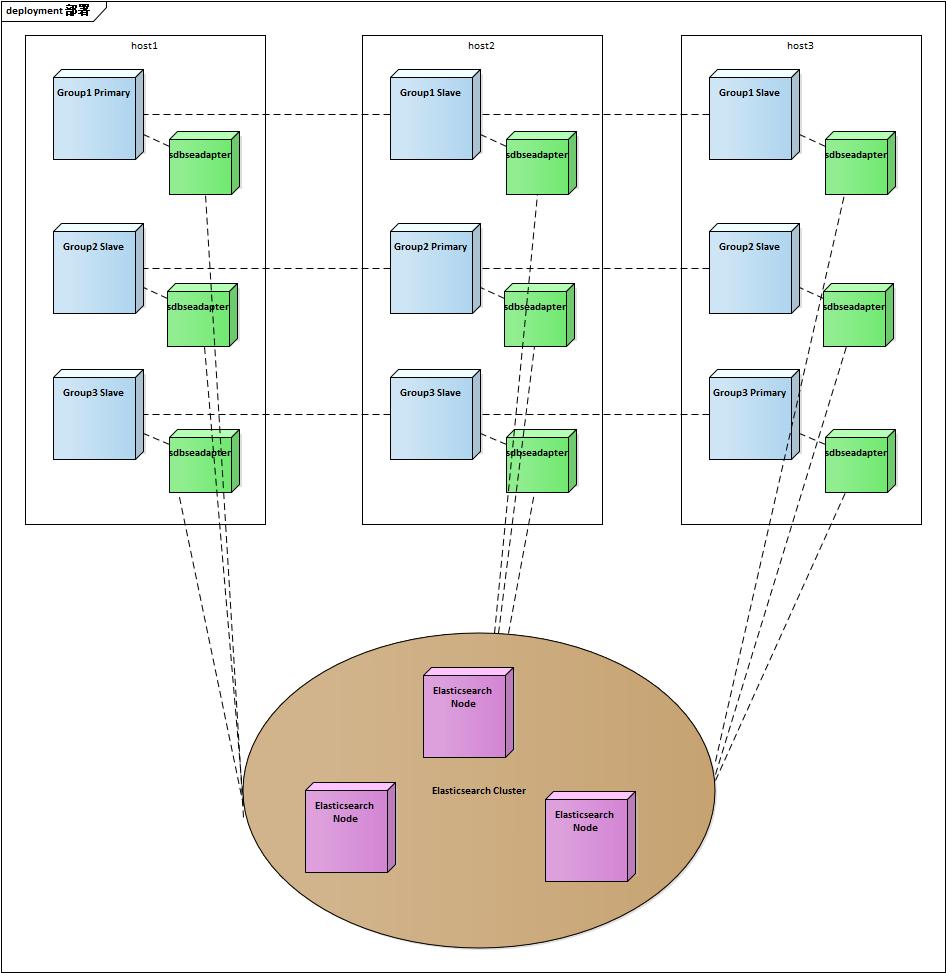
全文检索实现的是“近实时”的搜索能力,即一个新的文档从被索引到可被搜索,会有一定的延迟。在 SequoiaDB 的实现中,其延迟更多地取决于索引的速度。主要分两种情况:
- 创建索引时,集合中已存在大量的数据。此时要全量索引集合中的所有文档,耗时从分钟级到若干小时不等,取决于数据规模、搜索服务器性能等因素。如果在全量索引完成之前进行查询,只能查到部分结果。
- 在空集合或者只有很少量数据的集合上创建全文索引。在写入压力不是太大的情况下,通常在若干秒(典型值如 1~5 秒)内,新增的数据即可被搜索到。
相关内容
- 全文检索环境部署
- 搜索引擎适配器
- 全文检索语法
