- 一个精巧的p2p网络实现
- 前言
- 源码
- 类图
- 流程图
- 解读
- 1.路由扩展
- 2.节点路由
- 3.节点保存
- 总结
- 参考
一个精巧的p2p网络实现
前言
加密货币都是去中心化的应用,去中心化的基础就是P2P网络,其作用和地位不言而喻,无可替代。当然,对于一个不开源的所谓私链(私有区块链),是否必要,尚无定论。
事实上,P2P网络不是什么新技术。但是,使用Node.js开发的P2P网络,确实值得围观。这一篇,我们就来看看Ebookcoin的点对点网络是如何实现的。
源码
主要源码地址:
peer.js: https://github.com/Ebookcoin/ebookcoin/blob/v0.1.3/modules/peer.js
transport.js: https://github.com/Ebookcoin/ebookcoin/blob/v0.1.3/modules/transport.js
router.js: https://github.com/Ebookcoin/ebookcoin/blob/v0.1.3/helpers/router.js
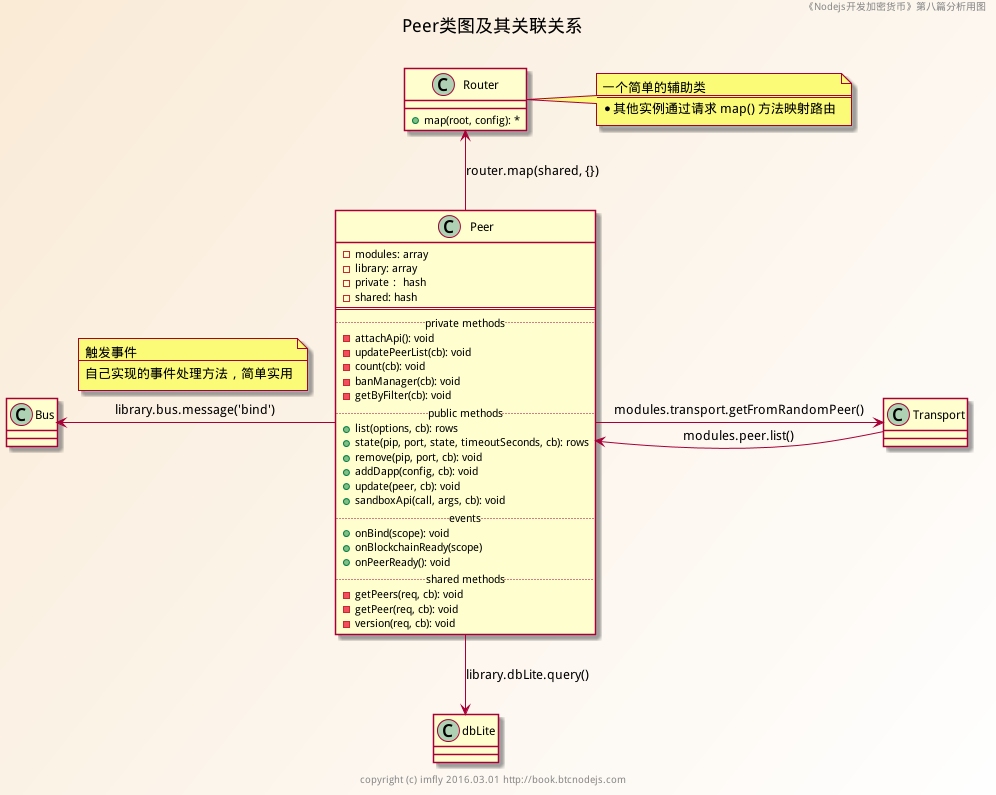
类图
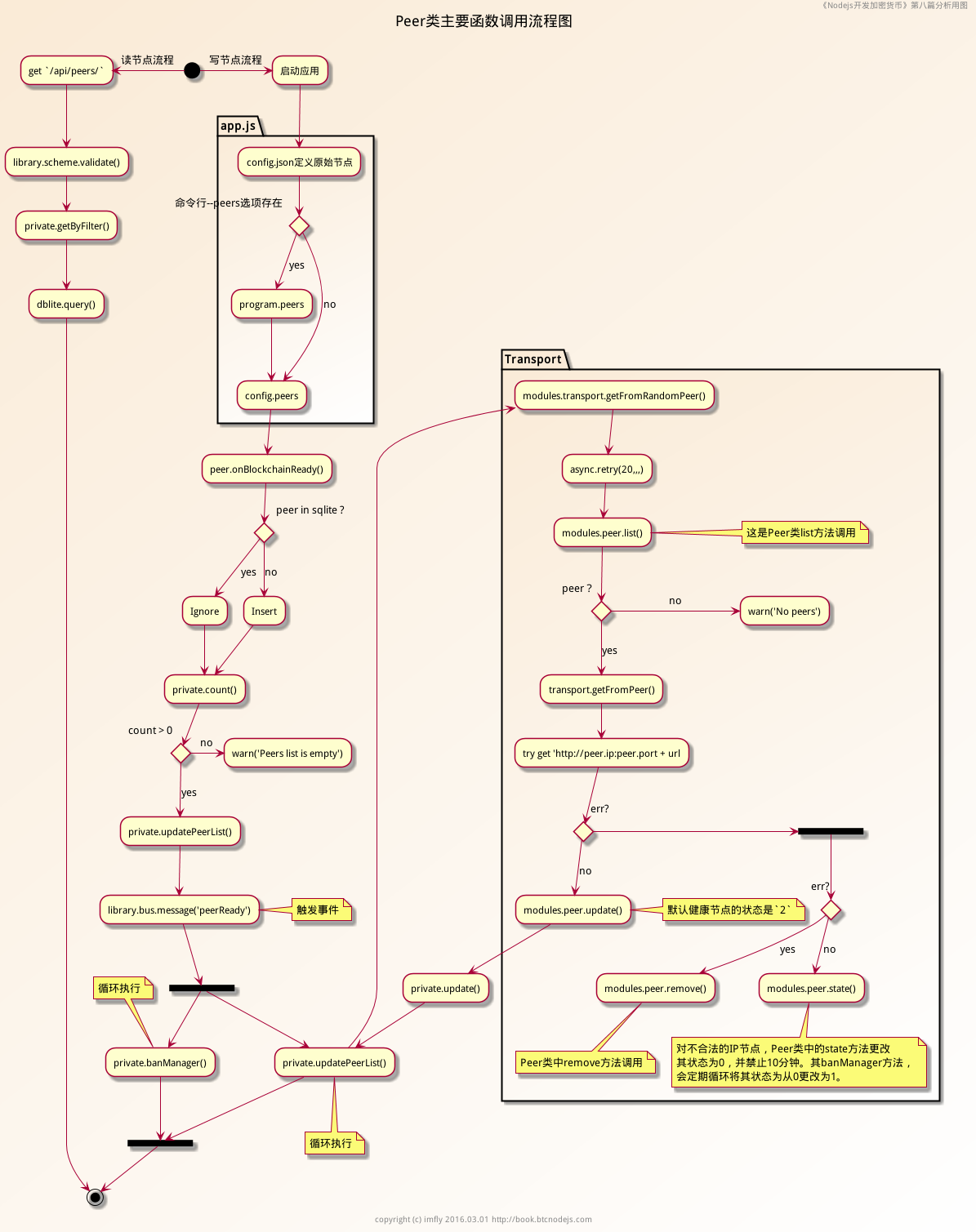
流程图
解读
基于http的web应用,抓住路由的定义、设计与实现,是快速弄清业务逻辑的简单方法。目前,分析的是modules文件夹下的各个模块文件,这些模块基本都是独立的Express微应用,在开发和设计上相互独立,各不冲突,逻辑清晰,这为学习分析,提供了便利。
1.路由扩展
任何应用,只要提供Web访问能力或第三方访问的Api,都需要提供从地址到逻辑的请求分发功能,这就是路由。Ebookcoin是基于http协议的Express应用,Express底层基于Node.js的connect模块,因此其路由设计简单而灵活。
前面,在入门部分,已经讲到对路由的分拆调用,这里是其简单实现。先看看helper/router.js吧。
// 27行var Router = function () {var router = require('express').Router();router.use(function (req, res, next) {res.header("Access-Control-Allow-Origin", "*");res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept");next();});router.map = map;return router;}...
这段代码定义了一个Express路由器Router,并扩展了两个功能:
- 允许任何客户端调用。其实,就是设置了跨域请求,选项
Access-Control-Allow-Origin设置为*,自然任何IP和端口的节点都可以访问和被访问。 - 添加了地址映射方法。该方法的主要内容如下:
// 3行function map(root, config) {var router = this;Object.keys(config).forEach(function (params) {var route = params.split(" ");if (route.length != 2 || ["post", "get", "put"].indexOf(route[0]) == -1) {throw Error("wrong map config");}router[route[0]](route[1], function (req, res, next) {root[config[params]]({"body": route[0] == "get" ? req.query : req.body}, function (err, response) {if (err) {res.json({"success": false, "error": err});} else {return res.json(extend({}, {"success": true}, response));}});});});}
该方法,接受两个对象作为参数:
- root: 定义了所要开放Api的逻辑函数;
- config: 定义了路由和root定义的函数的对应关系。
其运行的结果,就相当于:
router.get('/peers', function(req, res, next){root.getPeers(...);})
这里关键的小技巧是,在js代码中,对象也是hash值,root.getPeers() 与 root‘getPeers’ 是一致的。不过后者可以用字符串变量代替,更加灵活,有点像ruby里的元编程。这是脚本语言的优势(简单的字符串拼接处理)。
扩展一下,在类似sails的框架(基于express)里,很多都是可以使用类似config.json的文件直接配置的,包括路由。参考这个函数,很容易理解和实现。
2.节点路由
很轻松就能在peer.js里找到上述map方法的使用:
// 3行Router = require('../helpers/router.js')// 25privated.attachApi = function () {var router = new Router();router.use(function (req, res, next) {if (modules) return next();res.status(500).send({success: false, error: "Blockchain is loading"});});// 34行router.map(shared, {"get /": "getPeers","get /version": "version","get /get": "getPeer"});router.use(function (req, res) {res.status(500).send({success: false, error: "API endpoint not found"});});// 44行library.network.app.use('/api/peers', router);library.network.app.use(function (err, req, res, next) {if (!err) return next();library.logger.error(req.url, err.toString());res.status(500).send({success: false, error: err.toString()});});};
上面代码的34行,可以直观想象到,会有类似/version的路由出现,44行是express应用,这里就是将定义好的路由放在/api/peers前缀之下,可以确信peer.js文件提供了下面3个公共Api地址:
http://ip:port/api/peers/
http://ip:port/api/peers/version
http://ip:port/api/peers/get
当然,是不是可以直接这么调用,要看具体对应的函数是否还有其他的参数要求,比如:/api/peers/get,按照restful的api设计原则,可以理解为是获得具体某个节点信息,那么总该给个id之类的限定条件吧。看源码:
// 455行library.scheme.validate(query, {type: "object",properties: {ip_str: {type: "string",minLength: 1},port: {type: "integer",minimum: 0,maximum: 65535}},required: ['ip_str', 'port']}, function (err) {...// 480行privated.getByFilter({...});});
这里,在具体运行过程中,library就是app.js里传过来的scope,该参数包含的scheme代表了一个z_schema实例。
z_schema是一个第三方组件,具体请看参考链接。该组件提供了json数据格式验证功能。上述代码的意思是:对请求参数query进行验证,验证规则是:object类型,属性ip_str要求长度不小于1的字符串,属性port要求0~65535之间的整数,并且都不能空(必需)。
这就说明,我们应该这样请求http://ip:port/api/peers/get?ip_str=0.0.0.0&port=1234,不然会返回错误信息。回头看看getPeers方法的实现,没有required字段,对应可以直接访问http://ip:port/api/peers/。
看480行,上面的地址,都会调用privated.getByFilter(),并由它从sqlite数据库里查询数据表peers。这里涉及到 dblite第三方组件 (请看参考链接),对请求操作sqlite数据库进行了简单封装。
3.节点保存
大多数应用,读数据相对简单,难在写数据。上面的代码,都是get请求,可以查寻节点及其信息。我们自然会问,查询的信息从哪里来?初始的节点在哪里?节点变更了,怎么办?
(1)初始化节点
从现实角度考虑,在一个P2P网络中,一个孤立的节点,在没有其他任何节点信息的情况下,仅仅靠网络扫描去寻找其他节点,将是一件很难完成的事情,更别提高效和安全了。
因此,在运行软件之前,初始化一些节点供联网使用,是最简单直接的解决方案。这个在配置文件config.json里,有直接体现:
// config.json 15行"peers": {"list": [],"blackList": [],"options": {"timeout": 4000}},...
list的数据格式为:
[{ip: 0.0.0.0,port: 7000},...]
当然,也可以在启动的时候,通过参数--peers 1.2.3.4:70001, 2.1.2.3:7002提供(代码见app.js47行)。
(2)写入节点
写入节点,就是持久化,或者保存到数据库,或者保存到某个文件。这里保存到sqlite3数据库里的peers表了,代码如下:
// peer.js 347行Peer.prototype.onBlockchainReady = function () {async.eachSeries(library.config.peers.list, function (peer, cb) {library.dbLite.query("INSERT OR IGNORE INTO peers(ip, port, state, sharePort) VALUES($ip, $port, $state, $sharePort)", {ip: ip.toLong(peer.ip),port: peer.port,state: 2, //初始状态为2,都是健康的节点sharePort: Number(true)}, cb);}, function (err) {if (err) {library.logger.error('onBlockchainReady', err);}privated.count(function (err, count) {if (count) {privated.updatePeerList(function (err) {err && library.logger.error('updatePeerList', err);// 364行library.bus.message('peerReady');})library.logger.info('Peers ready, stored ' + count);} else {library.logger.warn('Peers list is empty');}});});}
这段代码的意思是,当区块链(后面篇章分析)加载完毕的时候(触发事件),依次将配置的节点写入数据库,如果数据库已经存在相同的记录就忽略,然后更新节点列表,触发节点加载完毕事件。
这里对数据库Sqlite的插入操作,插入语句是library.dbLite.query("INSERT OR IGNORE INTO peers,有意思的是IGNORE操作字符串,是sqlite3支持的(见参考),当数据库有相同记录的时候,该记录被忽略,继续往下执行。
执行成功,就会调用library.bus.message('peerReady'),进而触发peerReady事件。该事件的功能就是:
(3)更新节点
事件onPeerReady函数,如下:
// peer.js 374行Peer.prototype.onPeerReady = function () {setImmediate(function nextUpdatePeerList() {privated.updatePeerList(function (err) {err && library.logger.error('updatePeerList timer', err);setTimeout(nextUpdatePeerList, 60 * 1000);})});setImmediate(function nextBanManager() {privated.banManager(function (err) {err && library.logger.error('banManager timer', err);setTimeout(nextBanManager, 65 * 1000)});});}
两个setImmediate函数的调用,一个循环更新节点列表,一个循环更新节点状态。
第一个循环调用
看看第一个循环调用的函数updatePeerList,
privated.updatePeerList = function (cb) {// 53行modules.transport.getFromRandomPeer({api: '/list',method: 'GET'}, function (err, data) {...library.scheme.validate(data.body, {...// 124行self.update(peer, cb);});}, cb);});});};
看53行,我们知道,程序通过transport模块的.getFromRandomPeer方法,逐个随机的验证节点信息,并将其做删除和更新处理。如此一来,各种调用关系更加清晰,看流程图更加直观。.getFromRandomPeer的代码:
// transport.js 474行Transport.prototype.getFromRandomPeer = function (config, options, cb) {...// 481行async.retry(20, function (cb) {modules.peer.list(config, function (err, peers) {if (!err && peers.length) {var peer = peers[0];// 485行self.getFromPeer(peer, options, cb);} else {return cb(err || "No peers in db");}});...};
代码很简单,重要的是理解async.retry的用法(下篇技术分享,详细学习),该方法就是要重复调用第一个task函数20次,有正确返回结果就传给回调函数。这里,只要查到一个节点,就会传给485行的getFromPeer函数,该函数是检验处理现存节点的核心函数,代码如下:
// transport.js 500行Transport.prototype.getFromPeer = function (peer, options, cb) {...var req = {// 519行: 获得节点地址url: 'http://' + ip.fromLong(peer.ip) + ':' + peer.port + url,...};// 532行: 使用`request`组件发送请求return request(req, function (err, response, body) {if (err || response.statusCode != 200) {...if (peer) {if (err && (err.code == "ETIMEDOUT" || err.code == "ESOCKETTIMEDOUT" || err.code == "ECONNREFUSED")) {// 542行: 对于无法请求的,自然要删除modules.peer.remove(peer.ip, peer.port, function (err) {...});} else {if (!options.not_ban) {// 549行: 对于状态码不是200的,比如304等禁止状态,就要更改其状态modules.peer.state(peer.ip, peer.port, 0, 600, function (err) {...});}}}cb && cb(err || ('request status code' + response.statusCode));return;}...if (port > 0 && port <= 65535 && response.headers['version'] == library.config.version) {// 595行: 一切问题都不存在modules.peer.update({ip: peer.ip,port: port,state: 2, // 598行: 看来健康的节点状态为2...});}
这里最重要的是532行,request第三方组件的使用,请看参考链接。官方说request为简单的http客户端,功能足够强大,可以模拟浏览器访问信息,经常被用来做测试。
第二个循环调用
第二个循环调用的函数很简单,就是循环更改state和clock字段,主要是将禁止的状态state=0,修改为1,如下:
// 142行privated.banManager = function (cb) {library.dbLite.query("UPDATE peers SET state = 1, clock = null where (state = 0 and clock - $now < 0)", {now: Date.now()}, cb);}
综上,整个P2P网络的读写和更新都已经清楚,回头再看活动图和类图,就更加明朗了。
最后,补充一下数据库里,节点表格peers的字段信息:id,ip,port,state,os,sharePort,version,clock
总结
本篇,重点阅读了peer.js文件,学习了一个使用Node.js开发的P2P网络架构,其特点是:
- 产品提供初始节点列表,保障了初始化节点快速完成,不至于成为孤立节点;
- 节点具备跨域访问能力,任何节点之间都可以自由访问;
- 节点具备自我更新能力,定期查询和更新死掉的节点,保障网络始终畅通;
一旦达到一定的节点数量,就会形成一个互联互通的不死网络。搭建在这种网络上的服务,会充满怎样的诱惑?加密货币为什么会被认为是下一代互联网?这加起来不足千行的代码,可以给我们足够多的遐想空间。
这部分代码,涉及到dblite,request,z_schema等第三方组件,以及Ebookcoin自行实现的事件处理方法library.bus(在app.js文件的行),都很简单,不再分享或赘述,请自行查阅。本篇涉及的代码中,关于回调的设计很多,值得总结和研究。async组件,被反复使用,有必须汇总一下,请关注后续的技术分享。
参考
z_schema组件: https://github.com/Ebookcoin/z_schema
dblite组件: https://github.com/Ebookcoin/dblite
request组件: http://github.com/request/request
SQL As Understood By SQLite: https://www.sqlite.org/lang_conflict.html
