- 区块链
- 前言
- 源码
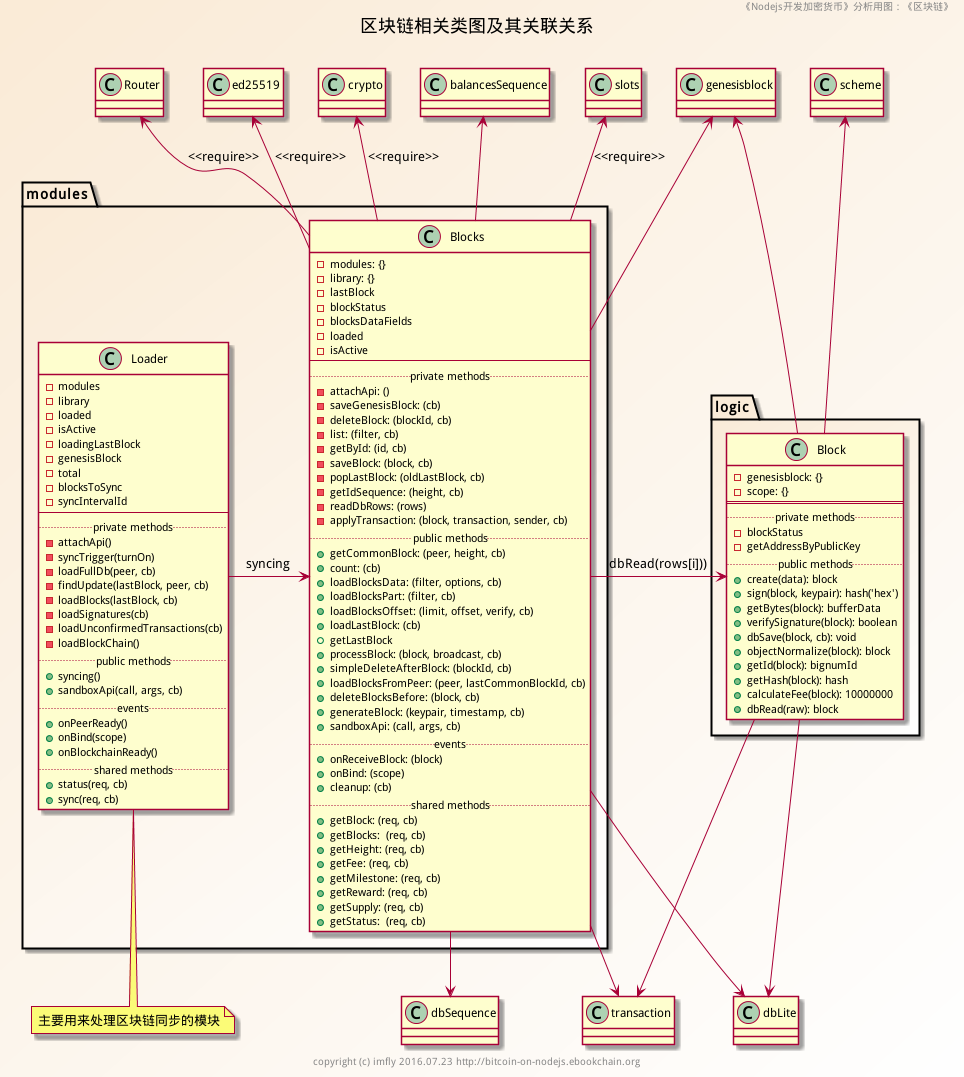
- 类图
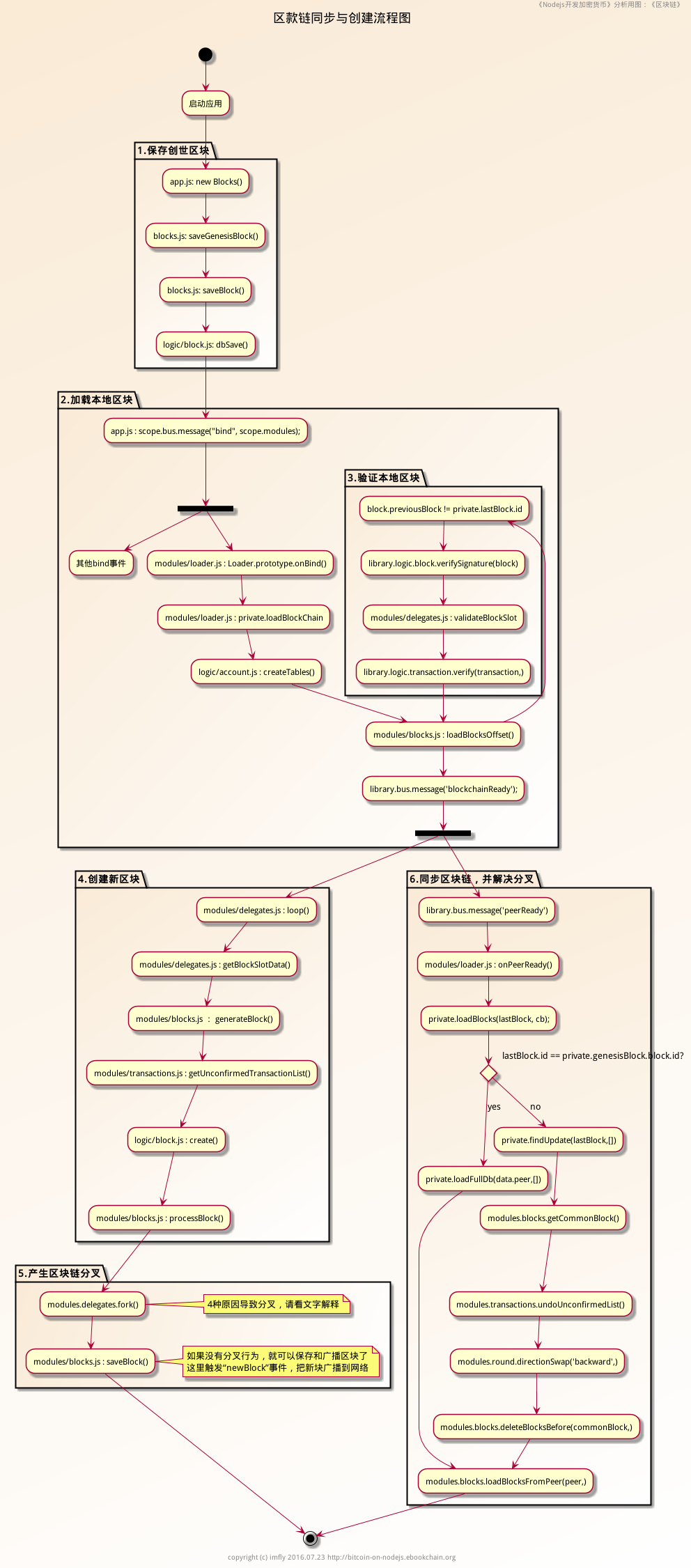
- 流程图
- 解读
- 1.区块链是什么?
- 2.区块链的特点
- 3.区块链开发应该解决的问题
- 4.亿书区块链数据库设计
- 5.亿书区块链实现
- 总结
- 链接
- 参考
区块链
前言
亿书,是一款加密货币产品,用时髦的话说,更是一款实用的区块链产品。那么,区块链是什么?有那些特点?最近,以太坊硬分叉事件给了我们很多启示,能不能彻底杜绝区块链分叉行为?这一章,我们通过认真阅读和理解亿书相关的代码逻辑,来详细解释和说明这些问题,以便更加深入的了解和学习这项技术。
源码
blocks.js https://github.com/Ebookcoin/ebookcoin/blob/v0.1.3/modules/blocks.js
block.js https://github.com/Ebookcoin/ebookcoin/blob/logic/block.js
loader.js https://github.com/Ebookcoin/ebookcoin/blob/v0.1.3/modules/loader.js
类图
流程图
解读
1.区块链是什么?
这里的区块链指狭义的区块链,是一种自引用的数据结构,可以存储成文件形式,不过多数产品存储在一个数据库中,比如比特币使用Google的LevelDB数据库存储。详细的概念解析,请看第一部分《区块链架构设计简介》,有助于更好的理解区块链概念。
(1)从数据库设计角度理解区块链
用数据库的概念理解,区块链就是一张“自引用”的数据库表。每条记录代表一个区块,这条记录(区块)记录着它前面(时间上)一条记录的信息,可以直接查询到前一条记录,因此从任何一条记录开始都可以往前顺序追溯,直到第一条记录。普通自引用表结构,通常使用ID作为关联外键,加密货币使用的是经过加密处理的信息字段,具有签名认证作用,可实现自我验证,防止被篡改。
与区块链直接关联的另一张重要的表,就是交易表。加密货币包含大量的交易,我们之前分析过,交易可以是加密货币,也可以是债权、股权或版权等各类数字资产,这些交易保存在一张独立表里,并与区块链形成多对一的关联方式。如此以来,只要追溯到区块,就很容易查询到该区块包含的交易记录。这样,一个公开透明、无法篡改、方便追溯的账本就形成了。
上面是从数据库查询(读数据)的角度考虑的,如果从写入的角度思考,就更有意思了。写入是要根据需求不同进行不同的编码,我们前面的章节说过,加密货币的各种功能都可以通过扩展交易类型进行编码,如果把一些现实中的合同规则进行编码,要求系统在某个条件下自动执行(写入或更新)某交易,自然也是件简单轻松的事情,这就是“智能合约”的简单理解。
我们在第一部分提到过“智能合约”的概念,在这里再次提及,作为程序员能够更加直观的去理解编码上的可行性。“智能合约”也是目前加密货币社区讨论火热的概念,可以发挥你想象的翅膀,从加密货币扩展到现实世界的各种场景,比如:自动贩卖机、销售终端、大公司间的电子数据交换、银行间用于转移与清算的支付网络,以及音乐、电影和电子书等数字版权交易等。
(2)形象化理解区块链
人们通常把具有先后顺序的数据结构,使用栈来表示,比特币白皮书把这种结构进一步形象化,第一个区块作为栈底,然后其他区块按照时间顺序依次堆叠在上面,这样一来,区块与首区块之间的距离就表示“高度”,“顶端”就表示最新添加的区块。每个区块包含大量交易,就是包含在对应栈里的数据。我们可以把这样的结构想象成一个大大的橱柜,区块就是其中一个抽屉,每个抽屉里是满满的交易,就象下面这样:
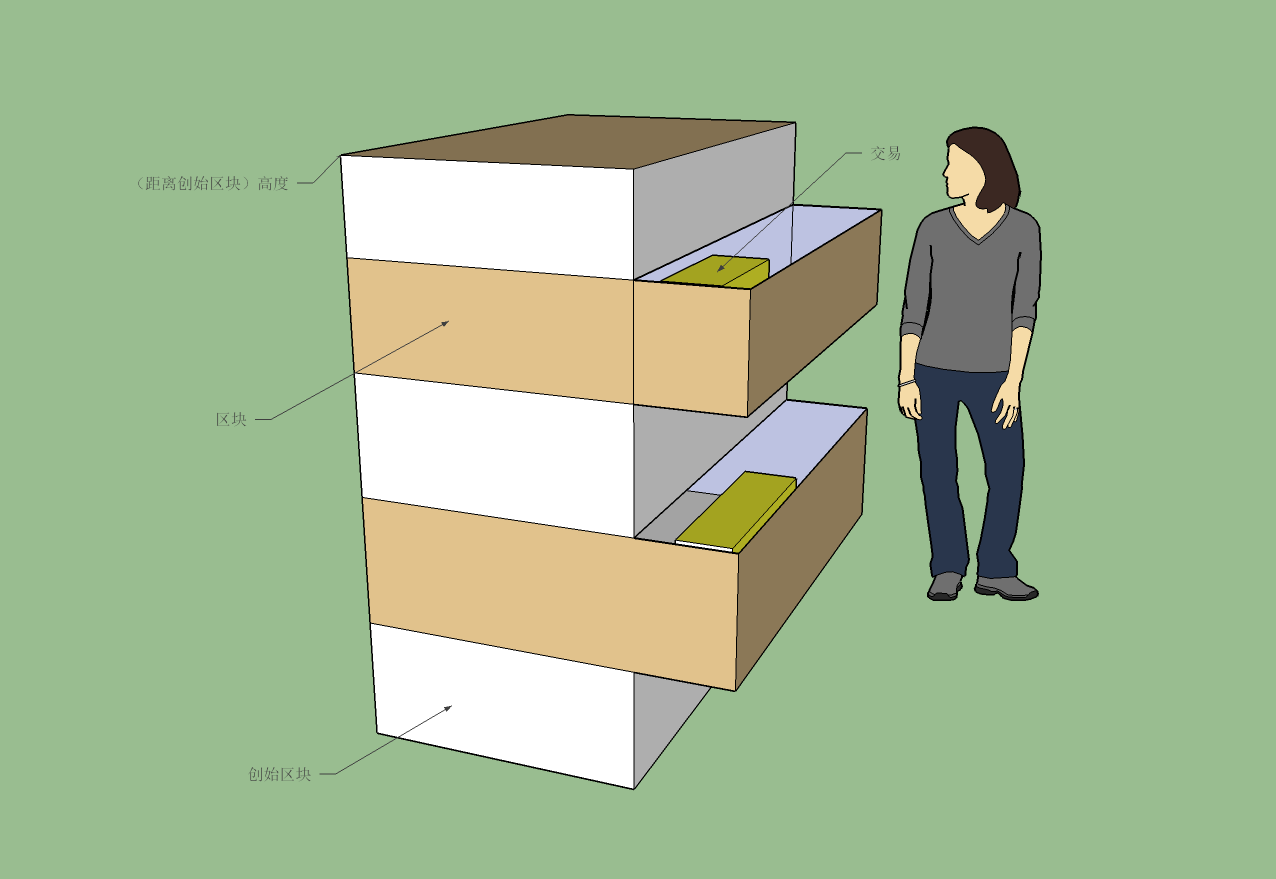
(3)区块链分叉
物理分叉。每一个区块都与它的前一区块(父区块)关联,而对它后面的区块(子区块)无限制,也就是说最顶端的区块,肯定知道它的父区块(已经写入区块链),但不知道子区块(或许还没有产生,也可能在传输的过程中)。我们知道,从物理层面,数据库、硬盘、网络的IO操作是最耗费时间的,在某一个时刻,多个最新区块同时找到父区块是很常见的现象,这就必然导致区块链分叉(从主链向多个方向发展)。这是在同一个软件版本(及其兼容版本)的情况下发生的,没有人为干预,不妨叫做物理分叉。
显然,物理分叉取决于物理环境,这与什么样的共识机制没有直接关系,不论是采取工作量证明机制(PoW)的比特币、还是采取股权证明机制(PoS)的点点币,亦或是这里采取授权股权证明机制(DPoS)的亿书币,都是如此。为了保持区块链的单一链条,解决分叉的最简单方式就是放任每个分叉继续增长,通常在下一刻就会出现差别,这时候软件选择最长的那个链条作为主链即可。在具体的设计开发过程中,这也是一个逻辑相对复杂的难点。
人为分叉。那么,如果存在人的干预,会怎么样呢?我们知道,世界上没有绝对完美的东西,人类开发设计的软件也不例外,漏洞是常有的,看看微软的windows系统时不时跳出来的漏洞修复提醒,就知道这类事情多么常见。而且,人类的需求始终在变化,软件要不断推出新功能来应对。所以,软件出现漏洞,或者添加新的功能,这类情况是再正常不过的事情。这时候,旧版本的软件对新版本软件产生的区块可能出现兼容性问题,甚至需要人为改变区块链的走向,这就导致新旧版本之间出现分叉,不妨叫做人为分叉。
很显然,人为分叉也是无法避免的事情。你可能认为很简单,有漏洞就修复吧,有新功能加上就得了,有什么好解释的。事实上,加密货币核心是交易,是价值转移的手段,规则的改变直接关系到所有持币人的利益。我们在第一部分说过,人是趋利的,要追求利益最大化,新功能能否保护用户的利益,还是代表了少部分利益集团的意志,应该如何约束和决策,这已经不单单是一个技术问题,更多的是社区政治问题,需要社区共同参与。历史证明,承载了较大资金盘的加密货币,在某一次分叉过程中,个别用户或矿工没有及时更新软件,就造成了直接经济损失。所以,每一个持币用户都非常关心任何一次分叉行为,都有可能站出来表达自己的意愿,甚至选择留在旧链上。
硬分叉和软分叉。它们都属于人为分叉,孰优孰劣也是当前社区分歧比较严重的问题。最初,社区区分这两个概念的简单方法就是,“硬分叉”是与旧版本的兼容度不高,但是获得了社区共识的规则明确的分叉行为,“软分叉”恰恰相反。发展到今天,只要是明确的“分叉”行为,大家都会寻求社区共识,所以二者的区别主要集中在软件兼容问题上了。这里的社区共识,是指包括软件开发者、矿工和使用者在内的整个软件社区,采取投票等方式,获得最大程度的一致性意见,通常是90%以上的社区成员同意就认为是达成了社区共识。比如最近以太坊为了应对The Dao遭受黑客攻击而实施的紧急硬分叉,就获得了社区87%的同意(接近90%,这里不讨论这次分叉行为的好坏)。
从技术角度讲,这里所谓的“硬”,主要体现在与旧版本的不兼容(或少量兼容)上,属于抛弃旧版本的行为,如果用户不升级软件,就永远留在旧链上,感觉上更加强硬得多。“软分叉”,最大程度的保持了对以前版本的兼容性,做得好的话,多个版本可以同时运行,类似于正常的版本迭代升级,用户可以自由选择是否升级。有人说“硬分叉”是很糟糕的事情,另一些人认为“软分叉”风险更大。事实证明,只要准备充分,操作得当,无论是“硬分叉”,还是“软分叉”,都不可怕,只不过“软分叉”在编码中需要考虑的情况更加复杂,对用户的影响较为隐蔽。
我个人不喜欢谈政治,但是作为交易媒介的新兴产物——加密货币,天生就是政治的附属品。这些货币的持续发展,往往是不同利益团体(包括开发者、矿工和用户)之间不断博弈的结果。最初是开发者主导,某个时期矿工的力量更加强大,后期用户的力量就不容忽视。也正是这些力量之间的制衡,才让加密货币相对持续稳健的发展,当这三种力量达到均衡的时候,就是这个加密货币相对成熟的时候。最近,以太坊硬分叉处理Dao遭受的黑客攻击事件,搅动了整个加密货币社区,不同利益者发出不同的声音,这是好事,充分说明加密货币仍处在初级阶段,还有很长的路要走。
2.区块链的特点
我们可以按照堆栈的方式理解数据结构,并采用自引用的关联方式设计数据库模型,但是做到这些,我个人认为并不代表就是区块链了,它还必须使用加解密技术,被置于去中心化的网络,由P2P网络节点共同维护,才能称得上区块链。当然,也有人持不同观点,他们认为一个中心化的应用,如果使用类似的数据结构,会更加安全(比不使用该结构的中心化系统),同时可以避免分叉,性能或许更高(比去中心化的系统),但事实上没有了P2P网络的支撑,这点改进算不上什么。我们之前分析过,P2P网络本身就是一条非常好的安全屏障,单点被攻击或被破解,对整个网络系统没有太大伤害,而任何中心化的系统仅仅相当于单节点,安全性大大降低。所以,为了那些许的性能改进,却要牺牲更好的安全性,有点得不偿失。
汇总以上信息,区块链应该具备这样几个特点:
- 分布存储:区块链处于P2P网络之中,无论什么公链、私链,还是联盟链,都要采取分布式存储,使用一种机制保证区块链的同步和统一;
- 公开透明:每个节点都有一个区块链副本,区块链本身没有加密,数据可以任意检索和查询,甚至可以修改(改了也没用);
- 无法篡改:这是加密技术的巧妙应用,每一区块都会记录前一区块的信息,并实现验证,确保无法篡改。这里的无法篡改不是不能改,而是局部修改的数据,无法通过验证,要想通过验证,必须修改整个区块链,这在理论上可行,操作上不可行;
- 方便追溯:区块链是公开的,从任一区块都可以向前追溯,直到第一个区块,并通过区块查到与之关联的全部交易;
- 存在分叉:这是由P2P网络等物理环境,以及软件开发实践过程决定的,人们无法根本性杜绝。
也正是因为这样的特点,区块链的概念才逐渐火爆起来。实践证明,区块链技术能实现一切中心化应用的场景,可以解决(或更好的解决)很多中心化应用无法解决的问题,比如分布式财务管理、分布式存储、知识产权保护、电子商务,乃至物联网,特别是对于金融业而言,资金清算、审计等等,成本会大幅度降低。亿书,就是利用它公开透明、可追溯的特点,与数字出版结合起来,实现自媒体和版权保护,彻底解决当前数字出版版权保护不力的顽疾。
3.区块链开发应该解决的问题
明白区块链是什么和基本原理之后,就可以着手设计其基本功能了。从需求的角度说,设计中需要做到如下几点:
(1)加载区块链。确保本地区块链合法,未被篡改。
- 保存创世区块
- 加载本地区块
- 验证本地区块
(2)处理新区块。加载后,该节点就可以处理网络中的交易了。
- 创建新区块;
- 收集整理交易,写入(关联)区块;
- 把新产生的区块写入区块链;
- 处理区块链分叉。
(3)同步区块链。确保本地区块链与网络中完整的区块链同步。
下面,我们从数据库设计出发,分别研读相关代码,认真讨论亿书区款链是如何运作的。
4.亿书区块链数据库设计
亿书使用SQLite数据库,与区块链相关的数据库结构如图:
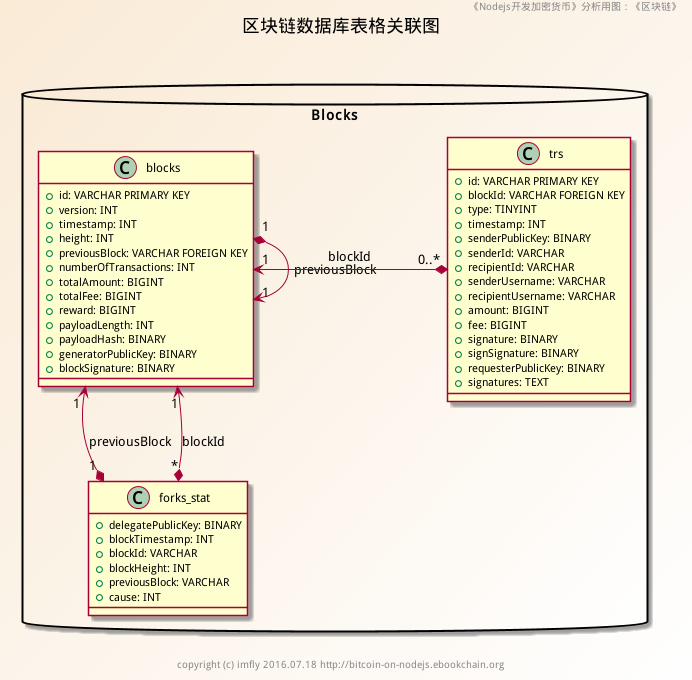
blocks表是区块链,trs表是各种交易,forks_stat表代表分叉状态。从关联关系上看,blocks首先是一个自引用表,使用previousBlock关联;与trs是一对多的关系,一条记录关联多条交易;与forks_stat也是一对多的关系,意思是有分叉。
5.亿书区块链实现
这里按照上面提到的开发区块链要解决的问题,逐一对照,查看亿书技术实现。
(1)保存创世区块
创世区块是硬编码到客户端程序里的,会在客户端运行的时候,直接写入数据库。这样做的好处是保证每个客户端都有一个安全、可信的区块链的根。
// modules/blocks.js// 78行function Blocks(cb, scope) {library = scope;// 80行genesisblock = library.genesisblock;self = this;self.__private = privated;privated.attachApi();// 85行privated.saveGenesisBlock(function (err) {setImmediate(cb, err, self);});}
这是modules/blocks.js模块的构造函数,在入口程序app.js运行的时候,直接创建该模块的实例,85行的代码privated.saveGenesisBlock方法直接运行。如果已经运行过,该方法就会返回,什么都不做。如果第一次运行,该方法就会直接保存创世区块(80行的genesisblock),接着调用266行的privated.saveBlock()方法(不再粘贴),把创世区块记录(包括交易)保存到数据库。
这是一个非常典型的区块创建过程,我们可以借机会看看一个区块(创世)的数据是什么样的:
// genesisBlock.json 文件{"version": 0,// 3行"totalAmount": 10000000000000000,"totalFee": 0,"reward": 0,"payloadHash": "1cedb278bd64b910c2d4b91339bc3747960b9e0acf4a7cda8ec217c558f429ad","timestamp": 0,"numberOfTransactions": 103,"payloadLength": 20326,"previousBlock": null,"generatorPublicKey": "b7b46c08c24d0f91df5387f84b068ec67b8bfff8f7f4762631894fce4aff6c75",// 1757行"height": 1,"blockSignature": "2985d896becdb91c283cc2366c4a387a257b7d4751f995a81eae3aa705bc24fdb950c3afbed833e7d37a0a18074da461d68d74a3a223bc5f8e9c1fed2f3fec0e","id": "8593810399212843182",// 12行。为了方便阅读,这里把关联的交易信息排版在最后位置"transactions": [{"type": 0,// 15行"amount": 10000000000000000,"fee": 0,"timestamp": 0,"recipientId": "6722322622037743544L","senderId": "5231662701023218905L","senderPublicKey": "b7b46c08c24d0f91df5387f84b068ec67b8bfff8f7f4762631894fce4aff6c75","signature": "aa413208c32d00b89895049ff21797048fa41c1b2ffc866900ffd97570f8d87e852c87074ed77c6b914f47449ba3f9d6dca99874d9f235ee4c1c83d1d81b6e07","id": "5534571359943011068"},{"type": 2,...},...{"type": 3,...}...]}
这些字段,我们在上面的数据库表里已经列出,下面看看几个关键数据:
3行:在创世区块设定初始代币总量,这里是1亿;
1757行:创世区块高度为1;
12行:区块必须包含交易,这里是3种类型的交易,之前分析过,它们分别是转账交易、受托人交易和投票交易。第1个转账交易,把初始区块的代币全部转到了另一个账户,这在实际的生产环境,特别是在ICO(预售)之后,可以直接转给参与众筹的实际用户。所以,创世区块有其非常实际的意义。其它两种交易,是支撑亿书共识机制的。
(2)加载本地区块
任何节点,都需要先加载验证本地区块链,确保没有被篡改。这个加载过程是软件初始化过程中的一部分,开发中不需要与网络节点联网等其他问题纠缠在一起。因此,代码需要被放在入口文件中去执行。我们在《入口程序app.js解读》一章里解读了app.js文件,但并不详细,仅仅梳理了程序的大致流程。这里重新提及,专注于区块链加载验证的问题,这在具体开发过程中,是很正常的增量开发的思路。
// app.js文件...ready: ['modules', 'bus', function (cb, scope) {// 435行scope.bus.message("bind", scope.modules);cb();}]
app.js文件 435行: 触发了“bind”事件(这是自定义的事件处理机制,请参考开发实践中关于事件循环的部分章节),会执行所有模块里的“onBind()”方法。该方法运行之前,各个模块仅仅被实例化,处于待命状态,所以“bind”事件是激活各模块的重要事件,是继各模块构造函数运行之后的关键方法(具体流程,请参考本部分第一章,模块的加载流程图)。大部分模块里的“onBind()”方法仅仅用来初始化某个变量,唯独loader.js模块,执行了下面的代码:
// modules/loader.js文件Loader.prototype.onBind = function (scope) {modules = scope;// 534行privated.loadBlockChain();};
modules/loader.js文件 534行: privated.loadBlockChain() 方法就是用来加载区块链的,内容如下:
// modules/loader.js文件privated.loadBlockChain = function () {var offset = 0, limit = library.config.loading.loadPerIteration;var verify = library.config.loading.verifyOnLoading;// 357行,闭包function load(count) {verify = true;privated.total = count;library.logic.account.removeTables(function (err) {if (err) {throw err;} else {library.logic.account.createTables(function (err) {if (err) {throw err;} else {// 369行async.until(function () {return count < offset;}, function (cb) {library.logger.info('Current ' + offset);setImmediate(function () {modules.blocks.loadBlocksOffset(limit, offset, verify, function (err, lastBlockOffset) {if (err) {return cb(err);}// 380行offset = offset + limit;privated.loadingLastBlock = lastBlockOffset;cb();});});}, function (err) {...// 398行library.logger.info('Blockchain ready');library.bus.message('blockchainReady');}}...}// 408行library.logic.account.createTables(function (err) {if (err) {throw err;} else {library.dbLite.query("select count(*) from mem_accounts where blockId = (select id from blocks where numberOfTransactions > 0 order by height desc limit 1)", {'count': Number}, function (err, rows) {...var reject = !(rows[0].count);modules.blocks.count(function (err, count) {...if (reject || verify || count == 1) {// 428行load(count);} else {// 其他情况,请查看源码...};
408行:将调用logic/account.js文件的createTables()方法,创建与用户相关的帐号信息表,全部以“mem_”开头,主要包括“mem_accounts”,“mem_accounts2contacts”,“mem_accounts2u_contacts”,“mem_accounts2delegates”,“mem_accounts2u_delegates”,“mem_accounts2multisignatures”,“mem_accounts2u_multisignatures”,“mem_round”等7个表。这些信息与用户相关,不需要被其他节点同步。
如果是新客户端,数据库为初始创建,创世区块第一次写入,count == 1,会立刻调用闭包load()函数(428行),加载验证缺失的区块。我们先不考虑其他情况,直接看357行的load()函数,可以发现该函数先删除帐号表格(removeTables),然后重建(createTables),并通过“async.until”方法(369行)进行循环加载区块链数据,具体方法是 modules/blocks.js的loadBlocksOffset()。当 count < offset 返回 “true” 的时候,循环结束,区块链数据同步完毕,然后触发 “blockchainReady” 事件(398行)。
这里的 “Offset” 不是分页数据,而是一次加载的区块数量,这样做的好处是避免一次性加载全部区块链,导致数据请求量过大,影响计算机性能。这个值最大是 limit 的值(380行),limit 等于 “config.json” 文件设定的全局变量 loading.loadPerIteration。用户可以修改该配置文件,在启动软件时通过命令行参数“-c”选择自己的配置文件,从而实现定制。如下:
// config.json文件// 132行"loading": {"verifyOnLoading": false,"loadPerIteration": 5000}
(3)验证本地区块
上面说到 modules/blocks.js 的 loadBlocksOffset() 方法才是处理加载的具体方法,也是验证的方法所在。
// modules/blocks.js文件Blocks.prototype.loadBlocksOffset = function (limit, offset, verify, cb) {...library.dbSequence.add(function (cb) {library.dbLite.query("SELECT " +...async.eachSeries(blocks, function (block, cb) {async.series([function (cb) {if (block.id != genesisblock.block.id) {if (verify) {// 627行 追溯区块if (block.previousBlock != privated.lastBlock.id) {return cb({message: "Can't verify previous block",block: block});}try {// 635行 验证块签名var valid = library.logic.block.verifySignature(block);}...if (!valid) {return cb({message: "Can't verify signature",block: block});}// 650行 验证块时段(Slot)modules.delegates.validateBlockSlot(block, function (err) {...}, function (cb) {// 先给交易排序,让投票或签名交易排在前面...async.eachSeries(block.transactions, function (transaction, cb) {if (verify) {modules.accounts.setAccountAndGet({publicKey: transaction.senderPublicKey}, function (err, sender) {...if (verify && block.id != genesisblock.block.id) {// 690行 验证交易library.logic.transaction.verify(transaction, sender, function (err) {...});} else {setImmediate(cb);}}, function (err) {if (err) {// 如果出现错误,要回滚async.eachSeries(transactions.reverse(), function (transaction, cb) {async.series([function (cb) {modules.accounts.getAccount({publicKey: transaction.senderPublicKey}, function (err, sender) {...modules.transactions.undo(transaction, block, sender, cb);});}, function (cb) {modules.transactions.undoUnconfirmed(transaction, cb);}...};
逐个加载区块,并验证:
627行:追溯前一区块,无法追溯自然是不正确的。
635行:验证块签名,防止块内容被篡改。建议认真阅读该行调用的签名验证方法“verifySignature()”(在“logic/block.js”文件的150行,请去源码库查看),这应该是对二进制数据(这里是区块数据)进行签名验证的典型用法。验证失败,就要终止整个循环,删除该块及其以后的块。
650行:验证块时段(Slot),防止块位置被篡改。实际上是变相验证了区块的高度及其时间戳(相关技术请看开发实践部分《关于时间戳及相关问题》的讨论)。亿书网络按照一定的周期循环(具体请参看《DPOS机制》),每一个块都可以根据其高度计算出它的出块时段,这与它的时间戳是对应的,这就锁定了区块位置,不然就是有问题。为什么要选择验证块时段,而不是简单直接的高度或时间戳?这是因为区块链有分叉的情况,相同高度存在多个块和时间戳,但相同的块时段却只能是一个。
690行:验证交易。具体流程请参考《交易》一章的相关内容。
(4)创建新区块
上面从设计的角度,正向提供了一种实现的思路。这里,我们反向阅读代码,不再思考为什么,仅仅查看是什么,体会一下读代码是多么简单的事情。注意的是,流程图需要反向查看。按照模块设计的基本原则,处理区块链的代码,都应该集中在“modules/blocks.js”文件里,所以,我们很容易就能找到创建新区块的代码“generateBlock()”方法,如下:
// modules/blocks.js文件// 1126行Blocks.prototype.generateBlock = function (keypair, timestamp, cb) {// 1127行 获取未确认交易,并再次验证,放入一个数组变量里备用var transactions = modules.transactions.getUnconfirmedTransactionList();var ready = [];async.eachSeries(transactions, function (transaction, cb) {...ready.push(transaction);...}, function () {try {// 1147行var block = library.logic.block.create({keypair: keypair,timestamp: timestamp,previousBlock: privated.lastBlock,transactions: ready});} catch (e) {return setImmediate(cb, e);}// 1157行self.processBlock(block, true, cb);});};
该方法很简单,1127行:获取未确认交易,并再次验证,放入一个数组变量“ready”里备用。从这里的处理方法可知道,与亿书区块关联的交易并没有实现比特币那样复杂的处理方法。比特币区块链中的所有交易,以二叉树(Merkle)表示,对于存储、维护、查询、验证交易都有很多便利。亿书目前的代码没有这样的优势,将在以后的版本中优化添加。
1147行:把整理好的数据组合成块数据结构(具体形式,类似于前面的创世区块),这里因为是新建数据,重要的是keypair、timestamp、previousBlock、transactions等四个字段信息。其他字段,诸如:totalFee、reward、payloadHash等,会在“processBlock()”(1157行)执行时处理。
这里的keypair、timestamp字段是该方法的参数,需要在调用的地方传入。我们查询代码发现,仅在“modules/delegates.js”文件里调用了该方法,其方法是“loop”,很显然该方法就是产生区块的入口方法,如下:
// modules/delegates.js// 492行privated.loop = function (cb) {...var currentSlot = slots.getSlotNumber();var lastBlock = modules.blocks.getLastBlock();...// 511行privated.getBlockSlotData(currentSlot, lastBlock.height + 1, function (err, currentBlockData) {...library.sequence.add(function (cb) {if (slots.getSlotNumber(currentBlockData.time) == slots.getSlotNumber()) {// 519行modules.blocks.generateBlock(currentBlockData.keypair, currentBlockData.time, function (err) {...});...};
去掉一些必要的判断,其实真正调用的时候,还是非常简单的。看上面“loop”方法,真正与“modules/delegates.js”模块关联的调用,是“privated.getBlockSlotData()”方法(470行),该方法从名字上理解就是获得块时段数据,为区块提供了密钥对和时间戳。由于是私有方法,可以猜想该方法一定与受托人有关系,让我们了解一下:
// modules/delegates.js// 470行privated.getBlockSlotData = function (slot, height, cb) {self.generateDelegateList(height, function (err, activeDelegates) {...for (; currentSlot < lastSlot; currentSlot += 1) {var delegate_pos = currentSlot % constants.delegates;var delegate_id = activeDelegates[delegate_pos];if (delegate_id && privated.keypairs[delegate_id]) {return cb(null, {time: slots.getSlotTime(currentSlot), keypair: privated.keypairs[delegate_id]});}}cb(null, null);});};
从代码可以看出,该方法先获得可以生产区块的受托人列表,然后根据当前时段信息找到激活的受托人标识,继而找到对应的密钥对,所以这个密钥对是与特定时段的特定受托人相关的。
接下来,要运行“privated.loop()”方法才可以实现新建区块的操作,所以继续搜索代码,我们很轻松找到:
// modules/delegates.js// 735行Delegates.prototype.onBlockchainReady = function () {privated.loaded = true;privated.loadMyDelegates(function nextLoop(err) {// 743行privated.loop(function () {setTimeout(nextLoop, 1000);});...
这是 “onBlockchainReady” 事件方法,上面分析了,当本地区块链加载完毕,就会调用该方法,也就是说,当区块链加载验证完毕,就可以创建新区块了。这里设定每秒钟(744行1000毫秒)调用一次“privated.loop()”方法,但是因为slot的限制,实际运行起来是每10秒产生一个块。
我们在上面的分析中知道,在同步缺失区块操作之前,还有一个更新节点信息的过程,这么一来,本地区块链加载完毕,创建新区块要比同步缺失的区块要早。这可以最大程度上保证节点创建区块的奖励,并让节点最大程度的服务亿书网络,当然,也增加了同步区块操作的难度。
(5)产生区块链分叉
具体到编码,区块链什么时候产生分叉?显然应该在新区块写入区块链的时候,也就是modules/blocks.js文件的1157行“processBlock()”执行的时候。检索该方法的调用,发现在1174行“onReceiveBlock()”方法里,以及1084行“loadBlocksFromPeer()”方法里,都调用了该方法,只有在“loadBlocksFromPeer()”方法里,“processBlock()”方法不执行广播操作。
该方法很长,但并不复杂,下面仅仅粘贴与分叉相关的源码,如下:
// modules/blocks.js文件// 800行Blocks.prototype.processBlock = function (block, broadcast, cb) {...if (block.previousBlock != privated.lastBlock.id) {// 859行 高度相同,父块不同modules.delegates.fork(block, 1);return done("Can't verify previous block: " + block.id);}//if (err) {// 877行 受托人时段不同modules.delegates.fork(block, 3);return done("Can't verify slot: " + block.id);}if (tId) {// 910行 交易已经存在modules.delegates.fork(block, 2);setImmediate(cb, "Transaction already exists: " + transaction.id);}};
上面列出了3种,还有一种:
// modules/blocks.js文件// 1166行Blocks.prototype.onReceiveBlock = function (block) {...if (block.previousBlock == privated.lastBlock.previousBlock && block.height == privated.lastBlock.height && block.id != privated.lastBlock.id) {// 1181行 高度和父块相同,但块ID不同modules.delegates.fork(block, 4);cb("Fork");}...
事实上,这里写入分叉的代码“modules.delegates.fork()”方法,很简单,仅仅是向“forks_stat”表插入对应数据而已。我们需要重点关注的是,上面罗列了4种分叉,它们的具体分叉的原因是:
- 859行:块高度相同,父块不同。可能是父块验证出现问题;
- 910行:交易已经存在。可能用户重复提交了交易,典型的就是“双花”问题;
- 877行:受托人时段不同。出现时段验证错误,而块时段是与时间戳相关的,所以可能是时间处理出现了问题;
- 1166行:高度和父块都相同,但块ID不同。这是接收来的块,高度比最新块大于1,父块是最新块时才会正常写入区块链,不然只能写入分叉。块的ID信息是对块进行sha256加密算法得出的结果,可能获得的是不同分支上的块。
(6)同步区块链,并解决分叉
我们上面说了,当加载验证本地区块结束,程序触发了“blockchainReady”事件(modules/loader.js 398行),于是各个模块里对应的“onBlockchainReady()”方法被执行。如果,查看每个模块对应的“onBlockchainReady()”方法,我们就能很轻松地了解,接下来程序在做什么。
这里,我们要考察如何从其他节点同步区块链,自然要看看节点模块里对应的方法。我们在《一个精巧的P2P网络实现》一章,已经贴出了“onBlockchainReady()”方法的代码,这里不再重复。请看对应源码的364行,该行在更新了节点之后,调用了“library.bus.message(‘peerReady’)”方法,触发了另一个“peerReady”事件。这才是我们最想要的,再次回到modules/loader.js文件,该文件也定义了“peerReady”事件,如下:
// modules/loader.js// 492行Loader.prototype.onPeerReady = function () {setImmediate(function nextLoadBlock() {...// 499行privated.loadBlocks(lastBlock, cb);...});setImmediate(function nextLoadUnconfirmedTransactions() {...// 514行privated.loadUnconfirmedTransactions(function (err) {...});setImmediate(function nextLoadSignatures() {...// 523行privated.loadSignatures(function (err) {...});};
该事件方法,通过“privated.loadBlocks()”等三个方法分别同步区块(499行)、未确认交易和签名。限于篇幅,我们仅分析“privated.loadBlocks()”方法,其他两个逻辑,请自行查阅源码。
// modules/loader.js// 225行privated.loadBlocks = function (lastBlock, cb) {// 226行modules.transport.getFromRandomPeer({api: '/height',method: 'GET'}, function (err, data) {var peerStr = data && data.peer ? ip.fromLong(data.peer.ip) + ":" + data.peer.port : 'unknown';...if (bignum(modules.blocks.getLastBlock().height).lt(data.body.height)) {...if (lastBlock.id != privated.genesisBlock.block.id) {// 259行privated.findUpdate(lastBlock, data.peer, cb);} else { // Have to load full db// 261行privated.loadFullDb(data.peer, cb);}...});};
226行的“transport.getFromRandomPeer()”方法,已经在《一个精巧的P2P网络实现》一章分析过,这里不再赘述。该方法通过随机选择节点,并调用这里提供的api获得远程节点的“height”数据,在确保本地区块链高度小于远程节点区块链高度的前提下,如果本地是创世区块就把远程节点整个数据库同步过来,调用“privated.loadFullDb()”方法,不然就调用“privated.findUpdate()”方法更新缺失的区块。前者很简单,属于后者的特殊情况,仅仅分析后者即可,代码如下:
// modules/loader.js// 75行privated.findUpdate = function (lastBlock, peer, cb) {...// 80行 获得正常块modules.blocks.getCommonBlock(peer, lastBlock.height, function (err, commonBlock) {...var toRemove = lastBlock.height - commonBlock.height;if (toRemove > 1010) {// 89行 该节点的分支太长,限制从该节点同步数据(1小时)library.logger.log("long fork, ban 60 min", peerStr);modules.peer.state(peer.ip, peer.port, 0, 3600);return cb();}// 暂存未确认的交易var overTransactionList = [];modules.transactions.undoUnconfirmedList(function (err, unconfirmedList) {...async.series([function (cb) {if (commonBlock.id != lastBlock.id) {// 还能反向循环modules.round.directionSwap('backward', lastBlock, cb);} else {cb();}},function (cb) {// 这里处理侧链library.bus.message('deleteBlocksBefore', commonBlock);// 117行 删除正常块之前的块modules.blocks.deleteBlocksBefore(commonBlock, cb);},...function (cb) {// 129行modules.blocks.loadBlocksFromPeer(peer, commonBlock.id, function (err, lastValidBlock) {...
这个方法相对比较复杂,80行,为什么是获得正常块(或标准块)?因为上面有4种分叉的块,都被保存在一个数据库表“blocks”里,需要通过查询把分叉的块(不正常的)过滤掉。89行,最新块与正常块之间高度差太大,说明该节点的分支太长,暂时限制从该节点同步数据,可以提高效率,也能减少出错几率。117行,把分叉的块删除掉,就解决了分叉问题。129行,这里就跟创世块处理方法相似了。
这里需要理解的是,真实的数据库存储的数据,绝对不是像前面描述的那样,是一个个标准的抽屉罗列在一起。很多情况下,正常的区块和分叉的区块都被按照时间顺序存储,是杂乱无章的,展示给用户的是经过代码过滤之后的数据。而我们定义的区块链,是经过编码实现的理想结果,这应该不难理解。
总结
本文从技术角度,描述了区块链的相关概念,并结合源码,解读了亿书区块链相关实现,这对于直观了解和学习区块链是有帮助的。特别是社区里,有些币圈网友认为压根就不应该有区块链分叉,本文的回答可能会让他们失望了。在现实世界,理想永远是遥不可及的事情,只有更好,没有最好。因此,包括区块链技术在内,只要是介入人类经济生态的应用,永远都不是单纯的技术性问题,它的更深层次的问题在于社区,以及基于人类经济生态的政治文化。
本文没有讨论区块链相关的公共Api,因为它们都是数据库读取操作,难度不大,按照以往的惯例,都留给读者自己去阅读。整体来说,这部分相对复杂,对于区块链分叉的处理,以及与区块关联的交易,还需要更多的优化,我们会在后续的版本中升级改造。
聪明的小伙伴一定看出来了,对于创建新区块、分叉等都是受托人模块(modules/blocks.js)的核心功能,受托人是DPOS机制的内容,所以要想更深层次的把握本章知识,还应该再深入一步,切实掌握亿书的共识机制。因此,请看下一篇:《DPOS机制》。
链接
本系列文章即时更新,若要掌握最新内容,请关注下面的链接
本源文地址: https://github.com/imfly/bitcoin-on-nodejs
亿书白皮书: http://ebookchain.org/ebookchain.pdf
亿书官网: http://ebookchain.org
亿书官方QQ群:185046161(亿书完全开源开放,欢迎各界小伙伴参与)
参考
《精通加密货币》作者Andreas问答
区块链
关于比特币硬分叉和软分叉的争议
以太坊软分叉失败,硬分叉成功
